Why
This project was born out of a real world need: VAT refund processing for tourists shopping in Dubai. When visitors make purchases in the UAE, they're eligible for VAT returns but claiming that refund requires passport verification at the point of sale. Rather than manually typing passport details (slow, error-prone, and frustrating for both staff and customers), we needed a fast, accurate way to capture document data directly.
tldr link: https://github.com/eringen/web-mrz-reader demo: https://eringen.com/workbench/web-mrz-reader/
What started as a passport-only reader quickly evolved. Customers presented national ID cards, residence permits, and various travel documents all with machine readable zones, but in different formats. That's when we expanded the reader to support all three ICAO document types.
What
The Machine Readable Zone is a standardized format defined by ICAO (International Civil Aviation Organization) in Doc 9303. It's the block of text printed in the OCR-B font at the bottom of passports, ID cards, and travel documents. Every international border checkpoint in the world can read it.
ICAO defines three MRZ formats, each designed for a different document size:
TD3 Passports
The most familiar format. Two lines, 44 characters each, totaling 88 characters.
P<UTOERIKSSON<<ANNA<MARIA<<<<<<<<<<<<<<<<<<<
L898902C36UTO7408122F1204159ZE184226B<<<<<10
Line 1 carries the document type (P for passport), issuing country, and the holder's name. Line 2 packs in the passport number, nationality, date of birth, gender, expiration date, personal number, and five check digits.
TD1 ID Cards
The most compact format, used on credit-card-sized ID documents. Three lines, 30 characters each, totaling 90 characters.
I<UTOD231458907<<<<<<<<<<<<<<<
7408122F1204159UTO<<<<<<<<<<<6
ERIKSSON<<ANNA<MARIA<<<<<<<<<<
TD1 distributes data across three shorter lines. Line 1 holds the document type, country, document number, and optional data. Line 2 carries dates, gender, nationality, and more optional data. Line 3 is dedicated entirely to the holder's name. This separation makes TD1 the only format where the name lives on its own line.
TD2 Travel Documents
A middle format for larger-than-ID-card but smaller-than-passport documents. Two lines, 36 characters each, totaling 72 characters.
I<UTOERIKSSON<<ANNA<MARIA<<<<<<<<<<<
D231458907UTO7408122F1204159<<<<<<06
TD2 is structured like TD3 but narrower the name shares line 1 with the document type and country, while line 2 mirrors the TD3 layout in a compressed form.
Comparing the Three Formats
| TD1 (ID Card) | TD2 (Travel Doc) | TD3 (Passport) | |
|---|---|---|---|
| Lines | 3 | 2 | 2 |
| Chars/line | 30 | 36 | 44 |
| Total | 90 | 72 | 88 |
| Name location | Line 3 | Line 1 | Line 1 |
| Check digits | 4 | 4 | 5 |
| Doc type prefix | I<, A<, C< | I<, A<, C< | P< |
All three formats share the same check digit algorithm but apply it to different field positions. TD3 has an extra check digit for the personal number field, which TD1 and TD2 don't have.
The Challenge
Traditional MRZ readers require specialized hardware infrared scanners or dedicated OCR devices costing thousands. We wanted something different: a solution that works with any smartphone or laptop camera, runs entirely in the browser, handles all three document formats, and keeps sensitive data private by never sending it to a server.
Our Approach
The entire solution is built with vanilla Javascript no frameworks, no build process, no bundler required. Just plain HTML and Javascript files served directly. This keeps the project simple, auditable, and eliminates tooling complexity.
1. Tesseract.js with Custom Training
The backbone is Tesseract.js, a Javascript port of the Tesseract OCR engine compiled to WebAssembly. The default English model struggles with MRZ because MRZ uses the OCR-B font and only 37 possible characters (A-Z, 0-9, <).
We trained a custom model specifically for MRZ recognition. This dramatically improved accuracy, especially for commonly confused characters:
0(zero) vsO(letter O)1(one) vsI(letter I)<(filler) vsKorX
2. Multi-Format Detection
The first challenge with supporting multiple formats is detection. A passport MRZ always starts with P<, but ID cards and travel documents use I<, A<, or C<. Our detection regex handles all of them:
function isMRZ(text) {
const mrzPattern = /[PIAC][A-Z<][A-Z]{3}[A-Z0-9<]+/;
return mrzPattern.test(text);
}
The pattern reads as: a document type character (P, I, A, or C), followed by a second type character or filler (<), then a three-letter country code, then the remaining MRZ characters.
3. Format Routing by Length
Once we detect and extract the MRZ string, we strip whitespace and determine the format purely by character count. This is reliable because the three lengths (90, 88, 72) don't overlap:
function parseMrz(mrz) {
if (mrz.length === 90) return parseTD1(mrz);
else if (mrz.length === 72) return parseTD2(mrz);
else if (mrz.length === 88) { /* TD3 parsing */ }
}
4. Format-Specific Parsing
Each format has its own parser because the field positions differ significantly.
TD1 splits the 90-character string into three lines of 30:
const line1 = mrz.slice(0, 30); // doc type, country, doc number, optional data
const line2 = mrz.slice(30, 60); // DOB, gender, expiry, nationality, optional data
const line3 = mrz.slice(60, 90); // full name (SURNAME<<GIVEN<NAMES)
TD2 splits into two lines of 36:
const line1 = mrz.slice(0, 36); // doc type, country, name
const line2 = mrz.slice(36, 72); // doc number, nationality, DOB, gender, expiry
TD3 splits into two lines of 44 the widest format with the most breathing room for long names.
5. Check Digit Validation
Every MRZ format includes check digits to catch OCR errors and tampering. The algorithm is the same across all formats a weighted sum using the repeating pattern 7, 3, 1:
function calculateCheckDigit(input) {
const weights = [7, 3, 1];
let sum = 0;
for (let i = 0; i < input.length; i++) {
const ch = input[i];
let value;
if (ch >= '0' && ch <= '9') value = ch.charCodeAt(0) - '0'.charCodeAt(0);
else if (ch >= 'A' && ch <= 'Z') value = ch.charCodeAt(0) - 'A'.charCodeAt(0) + 10;
else value = 0;
sum += value * weights[i % 3];
}
return sum % 10;
}
What differs across formats is which fields are validated and where the check digits sit:
| Check | TD1 | TD2 | TD3 |
|---|---|---|---|
| Document number | line1[14] | line2[9] | line2[9] |
| Date of birth | line2[6] | line2[19] | line2[19] |
| Expiration date | line2[14] | line2[27] | line2[27] |
| Personal number | - | - | line2[42] |
| Composite | line2[29] | line2[35] | line2[43] |
The composite check digit is the most interesting it's calculated over a concatenation of multiple fields, acting as an overall integrity check. For TD1, this spans data from both line 1 and line 2. For TD2 and TD3, it covers selected ranges within line 2.
If any check digit fails, the reader displays a warning specifying which fields failed validation, signaling a likely OCR misread.
6. Visual Feedback
To help users position documents correctly, we draw bounding boxes around recognized text regions on the canvas overlay:
function drawBoundingBoxes(words) {
context.strokeStyle = 'red';
context.lineWidth = 2;
words.forEach((word) => {
const { bbox } = word;
context.strokeRect(bbox.x0, bbox.y0, bbox.x1 - bbox.x0, bbox.y1 - bbox.y0);
});
}
Privacy by Design
A critical design decision was keeping everything client-side. The document image and extracted data never leave the user's browser. The entire OCR process runs locally via WebAssembly:
- No server uploads
- No API calls with personal data
- No data retention
This makes the solution suitable for privacy-sensitive environments where transmitting document data to external servers isn't acceptable.
Technical Architecture
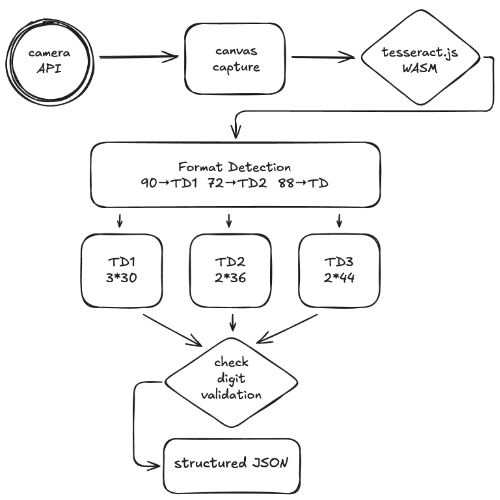
Results
The reader achieves high accuracy on well-lit, properly positioned documents. Recognition takes 1-3 seconds depending on device capabilities, with SIMD-enabled browsers seeing the fastest results.
TD3 passport output:
{
"Nationality": "UTO",
"Surname": "ERIKSSON",
"Given Names": "ANNA MARIA",
"Passport Number": "L898902C3",
"Issuing Country": "UTO",
"Date of Birth": "740812",
"Gender": "Female",
"Expiration Date": "120415",
"Personal Number": "ZE184226B",
"Validation": { "isValid": true }
}
TD1 ID card output:
{
"Document Type": "I",
"Nationality": "UTO",
"Surname": "ERIKSSON",
"Given Names": "ANNA MARIA",
"Document Number": "D23145890",
"Issuing Country": "UTO",
"Date of Birth": "740812",
"Gender": "Female",
"Expiration Date": "120415",
"Optional Data 1": "",
"Optional Data 2": "",
"Validation": { "isValid": true }
}
TD2 travel document output:
{
"Document Type": "I",
"Nationality": "UTO",
"Surname": "ERIKSSON",
"Given Names": "ANNA MARIA",
"Document Number": "D23145890",
"Issuing Country": "UTO",
"Date of Birth": "740812",
"Gender": "Female",
"Expiration Date": "120415",
"Optional Data": "",
"Validation": { "isValid": true }
}
Lessons Learned
- Custom training matters - Generic OCR models struggle with MRZ's specific character set and font. A dedicated model trained on OCR-B with only 37 character classes dramatically outperforms general-purpose text recognition.
- WebAssembly is production-ready - Running Tesseract in the browser via WASM provides near-native performance with zero server infrastructure.
- Camera quality varies wildly - Desktop webcams, phone cameras, and tablets all produce different results. Good lighting and a steady hand are more important than resolution.
- The MRZ spec is well-designed - Check digits, fixed positions, and a limited character set make parsing reliable once OCR accuracy is high enough. The composite check digit is particularly clever - it catches errors that individual field checks might miss.
- Format detection by length just works - Since TD1 (90), TD2 (72), and TD3 (88) have distinct character counts, a simple length check after stripping whitespace is a reliable and foolproof way to route parsing.
- Field layout differences matter - TD1 puts the name on its own line while TD2 and TD3 pack it into line 1 alongside other data. TD1 spreads data across three lines while the others use two. These structural differences require dedicated parsers rather than a one-size-fits-all approach.
Try It Yourself
Direct try: https://eringen.com/workbench/web-mrz-reader/
The project is open source and runs in any modern browser. Clone the repository, serve the files over HTTPS (or localhost), and point your camera at a passport or ID card. All processing happens on your device your data stays with you.
GitHub: https://github.com/eringen/web-mrz-reader
This project demonstrates how modern web technologies can deliver functionality that once required specialized hardware, all while respecting user privacy.